The task of the AI is the detection of the lane by processing an image as shown in the figure below.
The AI predicting the lane.
Architecture
There is one type of AI that performs best in object recognition on images, the convolutional neural network (CNN). Since we have an image as input and want an image as output, our network has an encoder with convolution and max-pooling layers and an decoder with deconvolution and upsampling layers. The figure below shows the architecture of the network. On the left side the encoder, and on the right side the decoder.
CNN architecture
Convolution
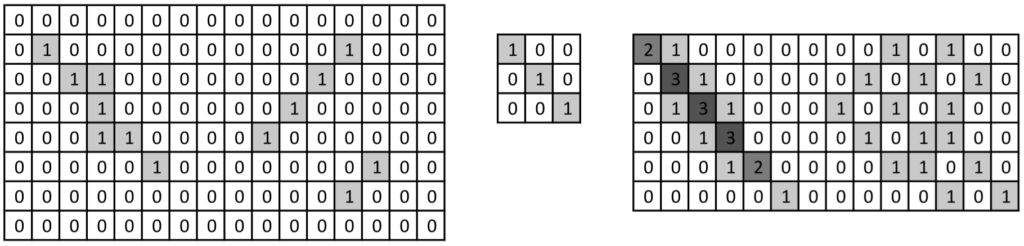
Since convolution is the main part of a CNN, lets take a look on how it works. The figure below shows the input image with size 16×8 on the left side. Applying the kernel size 3×3 (in the middle of the figure) on each pixel of the input image, the output with size 14×6 results (right side of the figure). In this context ‘applying’ means: Placing the kernel on the input image in the left upper corner, then multiplying each image pixel with the overlying kernel pixel, adding them up and storing them in the output image. Then move the kernel one pixel and repeat the process until the whole image is filtered.
Applying a left upper to right lower diagonal kernel on an image (left: input, middle: kernel, right: output).
Feature Maps
The figure below gives an insight into how the CNN works. Each block shows the feature maps (the output) of a layer.
input
feature maps after first convolution
feature maps after second convolution
feature maps after third convolution
feature maps after second upsampling
feature maps after fourth deconvolution
output
Previous
Next
The input and output images have size 40×20 pixel. The reason for such a low resolution is to save computing power. By applying a convolution each pixel needs at least one arithmetic operation.
Fixed-Point Model
For later use in the FPGA the trained floating-point model of the CNN was converted to a 1.15 fixed-point model. For conversion a Matlab script was implemented, which reads in a H5-file, reorders the weights and biases for better indexing while processing, converts them to fixed-point and writes them to a binary file.